
Looking for a needle in a haystack: The trials and tribulations of spatial sampling frames
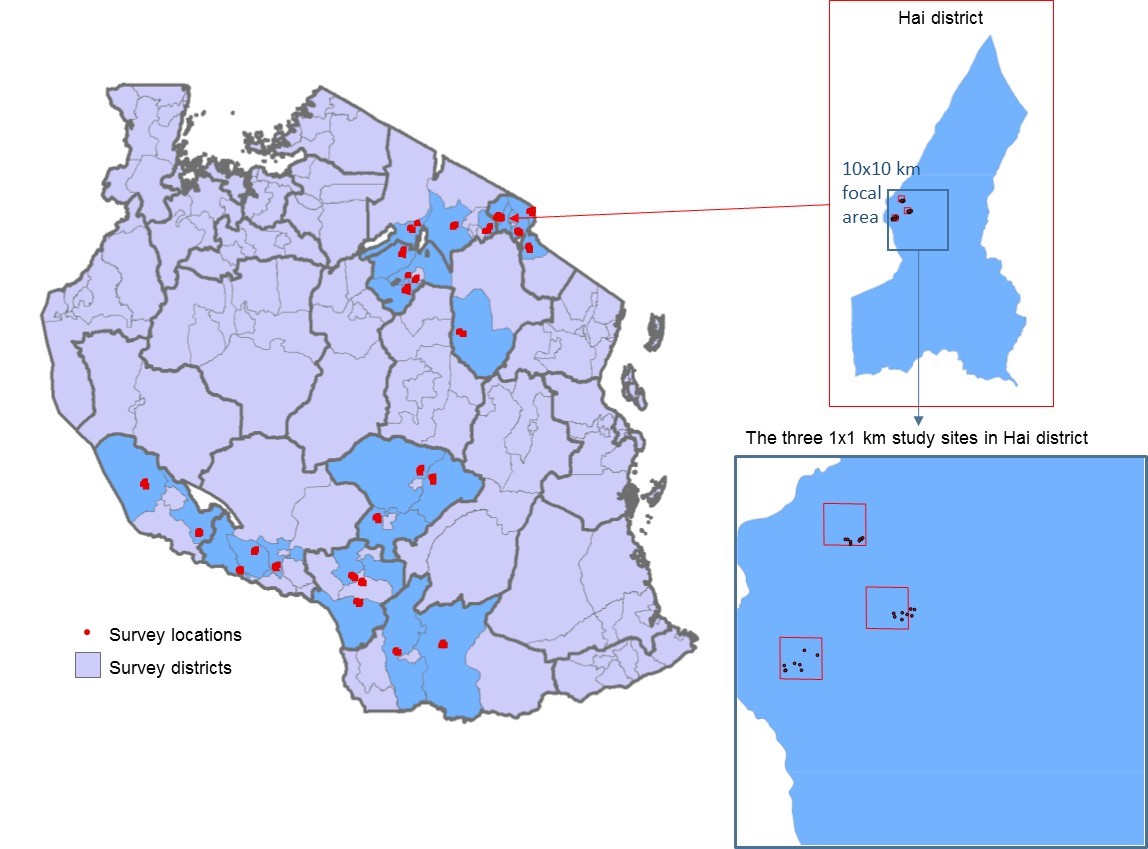
Collecting and using large amounts of geo-referenced data, all part of so-called ‘big data’, is all the rage these days. In TAMASA we have a spatial sampling frame for collecting household and farmer yield data, which on a map looks very neat and tidy, and eminently ‘doable’. For example, in Tanzania this frame covers 650 households located within 25 randomly located 10×10 km grids spread across Tanzania’s major maize growing areas in the Southern Highlands and Northern zone. Within each grid, surveyed households are drawn from a further randomly defined set of three 1×1 km grid cells.
So far, so good. Now to the tricky bits.
First, Tanzania is a large country and a quick look will show you how far apart these study sites are. As an example, we are currently in the process of conducting the annual Agronomic Panel Survey (APS) in the Southern Highlands. We started in Songea (Southern Highlands) which is among the first areas where maize was ready to harvest. The first grid cells to be surveyed were in Namtumbo (about 60 km from Songea) and then in Songea Rural, about 20 km from Songea town. On day 3 we travelled about 800 km to the next site, Sumbawanga Rural, and so on.
Second, our survey collects household data, soil samples, as well as crop cuts for yield estimation. This means we have to conduct the survey around harvest time, which gives us a limited time period in which to conduct the survey. Harvest times also vary substantially from grid cell to grid cell depending on altitudes and farmers’ planting dates, and the type of variety grown (long or short duration). So logistics are, quite frankly, a nightmare. There is no starting at point A and proceeding to point B, C, etc. The reality is more like A to C, to G to F, and T to V, including traversing from South to North and back again.
Third, a 10 x 10 km pixel does perhaps not sound too big, but 100 km2 is a big area, especially in (remote) rural areas with variable terrain and few, if any, roads. So, as mentioned already, we adopted a clustered sampling strategy within a 10 x 10 km grid, randomly choosing three 1 1 km cells with eight households in each to reduce the logistical challenge. In theory then, one team of enumerators can go to each of these 1 1 km cells and easily find the eight farmers and their fields. In practice?
 Well, first you have to find the farmer. Since many farmers in Tanzania do not live next to their fields, finding the homes tead is a challenge. Even when one has a GPS reading for the farmer’s homestead, locating these in variable terrain is really difficult, especially where there are fallow areas with 3 meter high grasses. It is like looking for the proverbial needle in a haystack. And with rivers and streams between you and the sought after GPS location or farmer homestead, getting close to a field with a vehicle can require long detours.
Well, first you have to find the farmer. Since many farmers in Tanzania do not live next to their fields, finding the homes tead is a challenge. Even when one has a GPS reading for the farmer’s homestead, locating these in variable terrain is really difficult, especially where there are fallow areas with 3 meter high grasses. It is like looking for the proverbial needle in a haystack. And with rivers and streams between you and the sought after GPS location or farmer homestead, getting close to a field with a vehicle can require long detours.
And if the farmer does not have a phone, there is no phone signal (very common), or the farmer’s phone number is unknown (or has changed) then be prepared; your day in the field has just become a lot longer because finding farmers – and upon return – your colleagues, has just got a whole lot more difficult!